import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")5 Análise de agrupamento de clientes do mercado
No cenário atual do varejo, tratar todos os clientes de forma idêntica é uma estratégia ineficiente e dispendiosa. Cada consumidor possui hábitos de compra, preferências e frequências distintas. A Análise de Agrupamento (Clustering) surge como uma ferramenta estatística para transformar bases de dados brutas em inteligência de negócio, permitindo a identificação de padrões ocultos sem a necessidade de rótulos prévios (Aprendizado Não Supervisionado).
O objetivo desta aula é aplicar o algoritmo K-Means para segmentar uma base de clientes de um mercado, permitindo que o gestor de marketing responda a perguntas como:
Quem são os nossos clientes “Premium” e como retê-los?
Quais clientes estão em risco de churn (abandono) e precisam de uma oferta de reativação?
Como otimizar o orçamento de marketing focando nos grupos com maior potencial de retorno?
5.1 Dados disponíveis
Os dados disponíveis para esta análise contemplam 11 variáveis que podem ser agrupadas em três pilares fundamentais para a segmentação de clientes no varejo:
Perfil Demográfico e de Crédito Fornecem o contexto socioeconômico do cliente, fundamentais para entender o poder de compra e o risco.
idade: Idade do cliente em anos.renda: Renda mensal declarada ou estimada.score_serasa: Indicador de comportamento financeiro e risco de crédito (essencial para ofertas de prazo ou cartões fidelidade).
Comportamento de Compra (RFM) Variáveis que capturam a Recência, Frequência e Valor (modelo RFM), o “coração” da análise de CRM.
dias_ult_compra(Recência): Quantidade de dias desde a última transação. Clientes com valores baixos são ativos; valores altos indicam risco de abandono.interesse(Frequência): Um proxy para a frequência de visita ao mercado.vlr_tran_total_6m(Valor): Gasto acumulado no último semestre, indicando o LTV (Lifetime Value) recente do cliente.
Mix de Consumo (Categorias) Permitem identificar as preferências e o estilo de vida do cliente (ex: o sommelier, o fã de churrasco, o focado em saúde). Todas as variáveis abaixo referem-se ao gasto acumulado nos últimos 6 meses:
gasto_vinho_6m: Consumo na categoria de vinhos e espumantes.gasto_queijo_6m: Consumo em queijos e laticínios finos.gasto_cerveja_6m: Consumo em cervejas e bebidas de malte.gasto_flv_6m: Gasto em Frutas, Legumes e Verduras (indica perfil focado em perecíveis e saudabilidade).gasto_mercearia_6m: Gasto em itens de despensa (arroz, feijão, limpeza), o núcleo do consumo doméstico.
DicaInsight de Negócio
A combinação dessas variáveis permitirá criar Personas. Por exemplo: um cliente com alto gasto_vinho_6m e alto score_serasa possui um perfil radicalmente diferente de um cliente com alto gasto_flv_6m e baixa idade. O K-Means nos ajudará a encontrar esses grupos de forma automatizada.
A análise será feita usando python. Começamos fazendo o carregamento das bibliotecas necessárias.
df = pd.read_csv("data/clientes_mercado.csv")
cols = list(df.columns)5.2 Análise Exploratória de Dados
Antes de aplicarmos qualquer algoritmo de agrupamento, precisamos conhecer a “matéria-prima” do nosso estudo. A análise exploratória nos ajuda a entender a dimensão dos dados, identificar valores atípicos (outliers) e observar como as variáveis de consumo se relacionam entre si.
Primeiro, verificamos o tamanho da nossa base para garantir que temos volume suficiente para uma segmentação estatisticamente relevante.
n_linhas = df.shape[0]
print(f"N~umero de linhas na base: {n_linhas}.")N~umero de linhas na base: 60000.Em seguida, visualizamos uma amostra aleatória dos dados para validar a estrutura das colunas e o formato das informações (tipos de dados e preenchimento).
df.sample(10) idade renda ... gasto_flv_6m gasto_mercearia_6m
27433 45 3969.65 ... 138.41 248.00
21745 43 7599.63 ... 10.45 61.06
47671 43 3948.80 ... 69.08 62.73
30046 47 4737.41 ... 76.61 18.48
51435 42 3590.90 ... 5.00 29.32
1299 41 2873.06 ... 0.00 29.69
32967 41 3418.86 ... 5.75 14.94
12510 41 3947.19 ... 10.85 0.00
32349 47 2762.79 ... 7.05 0.00
27238 46 2708.31 ... 6.06 0.00
[10 rows x 11 columns]A função describe() é fundamental para entender a distribuição de cada variável. Note os percentis extremos (1% e 99%): eles revelam a presença de clientes com comportamento muito fora da média, o que pode influenciar a posição dos centroides no K-Means.
print("Basic descriptive statistics:")Basic descriptive statistics:df.describe(percentiles = [.01, .1, .25, .5, .75, .9, .99]) idade renda ... gasto_flv_6m gasto_mercearia_6m
count 60000.000000 60000.000000 ... 60000.000000 60000.000000
mean 43.666067 4178.643589 ... 53.939280 56.954950
std 2.499092 1651.121300 ... 82.192656 91.350726
min 36.000000 831.610000 ... 0.000000 0.000000
1% 39.000000 1866.446500 ... 0.000000 0.000000
10% 41.000000 2492.791000 ... 0.000000 0.000000
25% 42.000000 2938.817500 ... 0.720000 1.260000
50% 43.000000 3638.325000 ... 10.870000 22.715000
75% 45.000000 5187.620000 ... 67.540000 56.420000
90% 47.000000 6994.165000 ... 202.241000 204.561000
99% 50.000000 8148.202900 ... 315.900200 394.280200
max 53.000000 9435.970000 ... 436.980000 631.680000
[12 rows x 11 columns]A matriz de correlação nos permite identificar quais variáveis “caminham juntas”. No contexto de um mercado, é comum observarmos correlações positivas entre categorias complementares (ex: Vinho e Queijo).
Variáveis com altíssima correlação (acima de 0.9) podem indicar redundância, enquanto variáveis com baixa correlação entre si são excelentes candidatas para diferenciar grupos de clientes (clusters) distintos.
correlation_matrix = df.corr()
plt.figure(figsize=(10, 8))
chart = sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
chart.set_xticklabels(chart.get_xticklabels(), rotation=45)
plt.title("Correlation Matrix")
plt.show()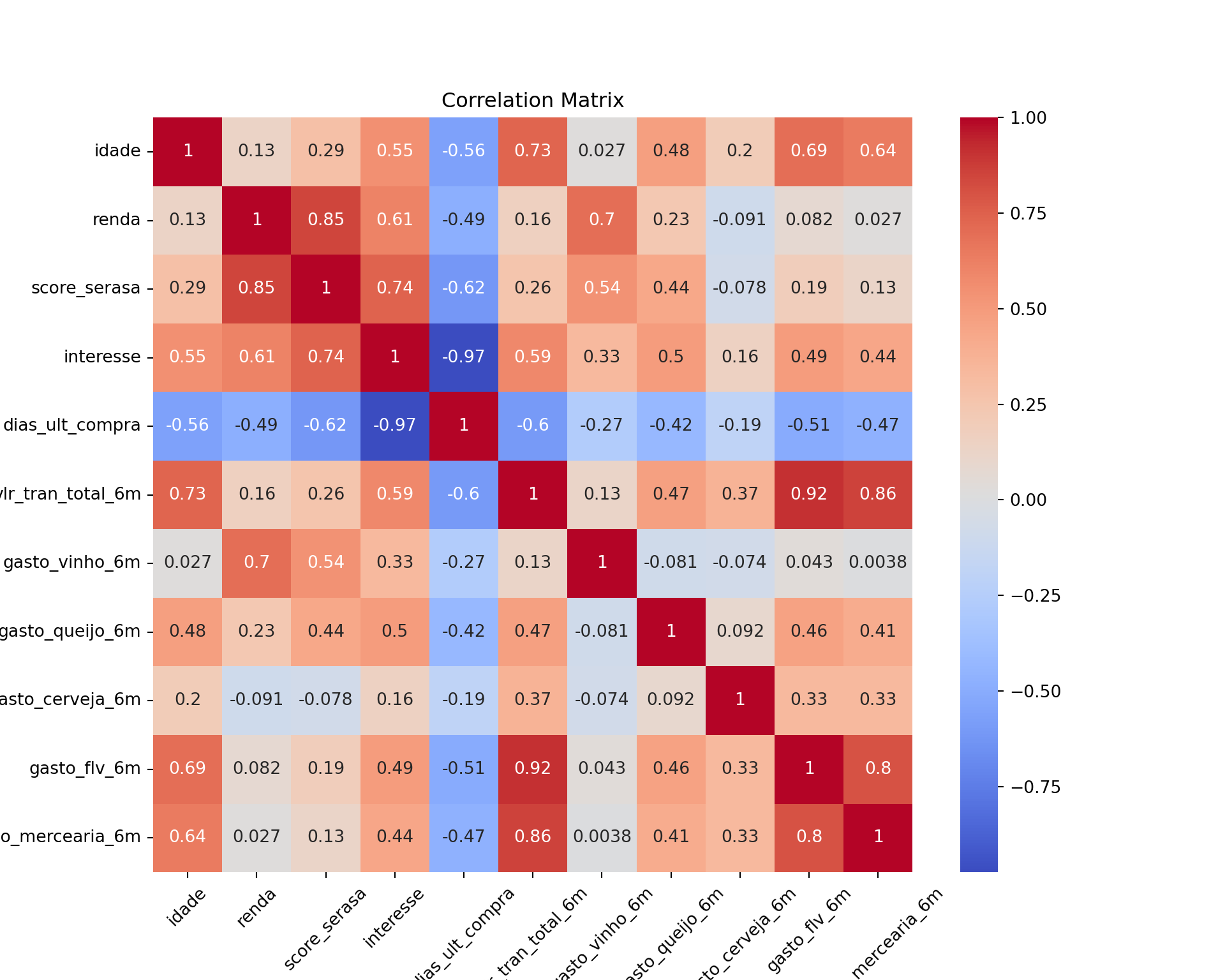
Após uma visão geral, vale a pena isolar as variáveis que descrevem a dinâmica de engajamento do cliente: Interesse (frequência), Recência (dias desde a última compra) e Valor (gasto total).
Este “trio” é a base do modelo RFM (Recency, Frequency, Monetary), uma das técnicas de segmentação mais clássicas do varejo. Esperamos ver aqui se clientes que compram com mais frequência (interesse) tendem a gastar mais (vlr_tran_total_6m) e se o tempo de inatividade (dias_ult_compra) tem uma correlação negativa com o valor total gasto.
cols_coorelation = ['interesse', 'dias_ult_compra', 'vlr_tran_total_6m']
correlation_matrix = df[cols_coorelation].corr()
plt.figure(figsize=(8, 6))
chart = sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm")
chart.set_xticklabels(chart.get_xticklabels(), rotation=45)
plt.title("Correlation Matrix")
plt.show()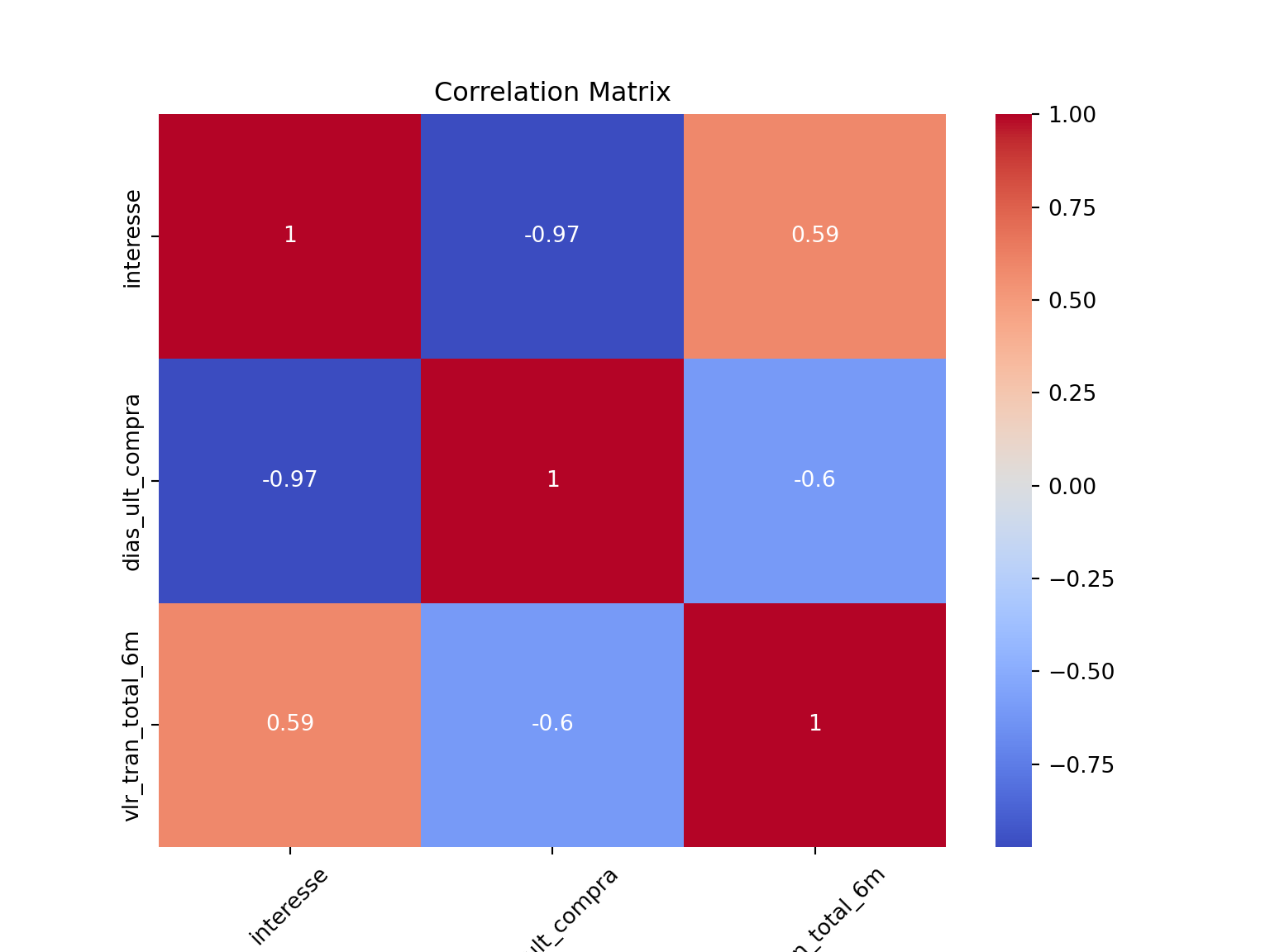
NotaO que observar?
Observe que a correlação entre dias_ult_compra e vlr_tran_total_6m é de -0.6.
Na prática, isso confirma que quanto maior o tempo que o cliente passa sem visitar o mercado (maior a recência), menor tende a ser o seu valor acumulado nos últimos 6 meses. Esse “esfriamento” do cliente é um sinal claro de churn (abandono). Para o gestor, esse número justifica investimentos em campanhas de win-back (re-engajamento) antes que o cliente ultrapasse uma determinada janela de dias sem compra.
def divide_chunks(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
num_cols = 4
num_rows = 2
total_plots = num_cols * num_rows
l_cols = list(divide_chunks(cols, num_cols))
for sub_cols in l_cols:
fig, axes = plt.subplots(num_rows, num_cols, figsize=(15,5))
for idx, col in enumerate(sub_cols):
data = df
ax_his = axes[0, idx]
ax_box = axes[1, idx]
ax_his.set_title(f"{col}")
sns.histplot(data=data, x=col, bins = "doane", stat="percent", color="#fec868", common_norm=False, ax=ax_his)
sns.boxplot(data=data, x=col, color = "#bdb2ff", flierprops={"marker": "x", "markersize": 0.001}, ax=ax_box)
ax_his.set_xlabel("")
ax_box.set_xlabel("")
axes = axes.ravel(order = "F")
for j in range(len(sub_cols)*3, num_cols * num_rows):
axes[j].axis("off")
plt.tight_layout()
plt.show()total_elementos = (len(cols) * (len(cols) - 1)) // 2
num_cols = 5
num_rows = int(np.ceil(total_elementos/num_cols))
fig, axes = plt.subplots(num_rows, num_cols, figsize=(20, 30))
idx_row_new, idx_col_new = 0, 0
df_sample = df.sample(200, random_state = 42)
for i, col_i in enumerate(cols):
for j, col_j in enumerate(cols):
if i < j:
ax = axes[idx_row_new, idx_col_new]
sns.scatterplot(data=df_sample, x=col_i, y=col_j, color="#bdb2ff", ax=ax)
idx_col_new += 1
if idx_col_new == (num_cols):
idx_row_new += 1
idx_col_new = 0
plt.tight_layout()
plt.show()5.3 Algoritmo k-médias
Nesta etapa, aplicamos o algoritmo K-Means para agrupar nossos clientes. O objetivo é que a variância dentro de cada grupo seja a menor possível, enquanto a diferença entre os grupos seja maximizada.
Conforme discutido anteriormente, a normalização é um passo crítico. Aqui, utilizamos o Z-score para garantir que variáveis como renda (na casa dos milhares) não dominem variáveis como interesse (unidades) apenas pela magnitude numérica.
normalize = True
df_cluster = df.copy()
if normalize:
df_cluster = (df_cluster - df_cluster.mean()) / df_cluster.std()
# df_cluster = (df_cluster - df_cluster.min()) / (df_cluster.max() - df_cluster.min()) ## min max
NotaHiperparâmetro k
Inicialmente, fixamos \(k=4\) com base em uma premissa de negócio (ex: perfis Bronze, Prata, Ouro e Diamante). Validaremos essa escolha tecnicamente ao final desta aula usando o Método do Cotovelo.
kmeans = KMeans(n_clusters = 4, random_state=42, init = 'k-means++', n_init = 1)
kmeans.fit(df_cluster)KMeans(n_clusters=4, n_init=1, random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
predict = kmeans.predict(df_cluster)
df_cluster["cluster"] = predict
df_cluster["cluster"] = [chr(x+65) for x in df_cluster.cluster]Após a convergência do algoritmo, precisamos “dar nome aos bois”. Para isso, desfazemos a normalização para observar as medianas reais de cada grupo e entender o volume de clientes em cada um.
DicaDica Analítica
Observe o campo Count. Clusters muito pequenos (ex: menos de 5% da base) podem indicar nichos muito específicos ou até mesmo outliers que o algoritmo isolou.
df_cluster = df.copy()
df_cluster["cluster"] = predict
df_cluster["cluster"] = [chr(x+65) for x in df_cluster.cluster]
df_cluster_info = df_cluster.groupby("cluster").median().reset_index()
df_cluster_count = df_cluster.groupby("cluster").count()["idade"].reset_index()
df_cluster_count.columns = ["cluster", "Count"]
df_cluster_table = pd.merge(df_cluster_info, df_cluster_count, how="left", on="cluster")
df_pivot = df_cluster_table.set_index('cluster').T
print(df_pivot)cluster A B C D
idade 42.000 48.00 43.00 44.000
renda 2983.460 3656.19 7166.71 5236.255
score_serasa 557.595 630.60 783.80 758.835
interesse 0.650 1.00 1.00 1.000
dias_ult_compra 61.000 4.00 22.00 29.000
vlr_tran_total_6m 158.165 2466.23 829.32 555.570
gasto_vinho_6m 0.000 0.55 110.76 0.000
gasto_queijo_6m 0.000 17.89 0.00 23.915
gasto_cerveja_6m 0.010 28.95 14.11 0.180
gasto_flv_6m 1.240 219.50 47.20 44.975
gasto_mercearia_6m 1.810 232.10 42.58 41.020
Count 30000.000 9987.00 9253.00 10760.000Definição da função utilizada para construção dos gráficos spider.
def make_spider(df_plot, n_cols = None):
num_col = df_plot.columns.difference(["cluster"])
if n_cols == None:
n_cols = df_plot['cluster'].unique().shape[0]
df_plot[num_col] /= df_plot[num_col].max()
df_plot = df_plot.fillna(0)
palette = plt.cm.get_cmap("Set2", len(df_plot.index))
# number of variable
categories = list(df_plot)[1:]
N = len(categories)
# What will be the angle of each axis in the plot? (we divide the plot / number of variable)
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1]
# Initialise the spider plot
my_dpi = 96
fig, axes = plt.subplots(df_plot.shape[0] // n_cols, n_cols, figsize=(1500/my_dpi, 1500/my_dpi), dpi=my_dpi, subplot_kw={"projection" : "polar"})
axes = axes.ravel()
for idx, ax in enumerate(axes):
color = palette(idx)
row = df_plot.iloc[idx]
# If you want the first axis to be on top: a
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
# Draw one axe per variable + add labels labels yet
ax.set_xticks(angles[:-1], categories, color='grey', size=7)
# Draw ylabels
ax.set_rlabel_position(0)
ax.set_yticks([0.33,0.66,0.99], ["0.3","0.6","1"], color="grey", size=10)
ax.set_ylim(0, 1)
# pegando valores
values = row.drop("cluster").values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, color=color, linewidth=1.5, linestyle='solid')
ax.fill(angles, values, color=color, alpha=0.4)
# Add a title
ax.set_title(f"Persona {row['cluster']}", size=14, color=color, y=1.1)
plt.tight_layout()
plt.show()Visualização dessas características com o gráfico spider.
make_spider(df_cluster_info)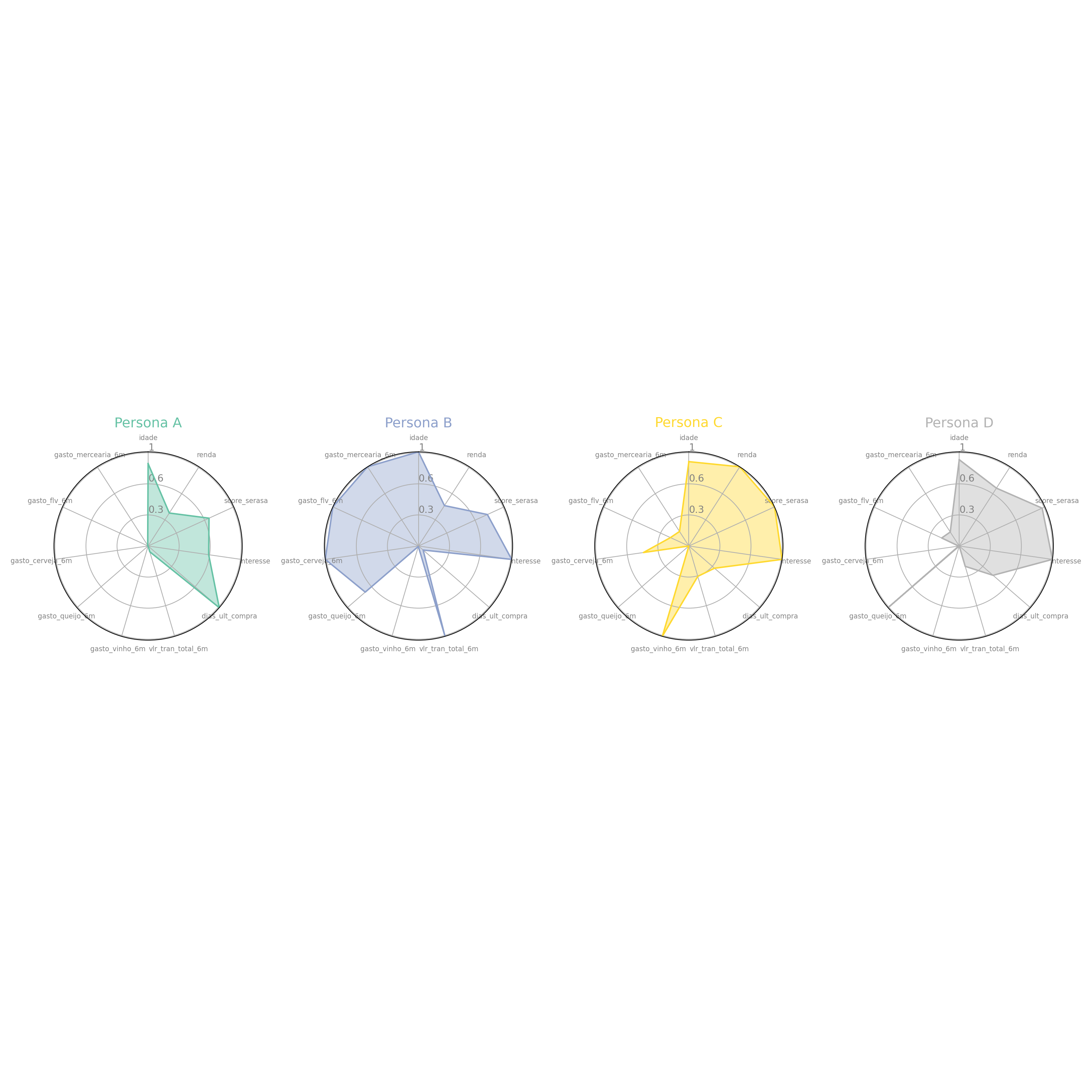
Com base na tabela e no gráfico acima, podemos desenhar o perfil comportamental de cada grupo. Esta etapa é fundamental para que o time de marketing saiba o que oferecer para quem.
Cluster A: O “Dormitório” ou Inativo
Perfil: É o maior grupo da base (30.000 clientes).
Comportamento: Possui a menor renda, o menor score e o menor interesse. O dado mais crítico é a recência: 61 dias desde a última compra e um gasto semestral irrisório (R$ 158).
Estratégia: Este grupo representa um risco de churn ou clientes que só compram itens em promoção extrema.
Ação: Campanha de reativação com cupons de desconto agressivos para trazê-los de volta à loja.
Cluster B: O “Fiel do Dia a Dia” (Heavy User)
Perfil: Renda moderada, mas o maior gasto total (R$ 2.466).
Comportamento: É o cliente dos sonhos. Compra quase todo dia (recência de 4 dias) e abastece a dispensa (mercearia) e a feira (FLV) no seu mercado. Curiosamente, não gasta quase nada em vinhos.
Estratégia: Manutenção de fidelidade.
Ação: Programa de pontos ou “mimos” em categorias de perecíveis para garantir que ele não mude para o concorrente.
Cluster C: O “Sommelier” de Alta Renda
Perfil: A maior renda da base (R$ 7.166) e o melhor score Serasa.
Comportamento: O gasto em vinhos é o mais alto disparado (R$ 110), enquanto o gasto em mercearia e FLV é baixo. Ele provavelmente compra itens específicos e caros, mas não faz a “compra do mês” no seu mercado.
Estratégia: Venda cruzada (Cross-sell) de itens premium.
Ação: Convites para degustações, ofertas de queijos importados e produtos gourmet.
Cluster D: O “Consumidor Equilibrado” (Standard)
Perfil: Renda e score intermediários.
Comportamento: Tem um comportamento de compra mais espaçado (29 dias) e foca em Queijos, FLV e Mercearia. É o cliente que faz compras de reposição.
Estratégia: Aumento de frequência.
Ação: Ofertas personalizadas via App para tentar diminuir o intervalo de 29 dias para 15 dias entre as compras.
ImportanteReflexão importante
O Cluster A representa mais de 50% da base total. Vale a pena gastar a mesma energia de marketing com ele do que com o Cluster B, que gasta 15 vezes mais? Essa é a base da segmentação estratégica!
5.3.1 Escolha do melhor valor de \(k\)
A escolha do número de grupos em uma análise de clustering não deve ser arbitrária. Para validarmos se \(k=4\) é uma escolha tecnicamente robusta, utilizamos o Método do Cotovelo (Elbow Method).
inertia = []
k_values = range(2, 8)
for k in k_values:
kmeans = KMeans(n_clusters=k, random_state=42, init='k-means++', n_init=10) # n_init=10 para melhores resultados
kmeans.fit(df_cluster.drop(columns=['cluster'], errors='ignore')) # Certifica que a coluna 'cluster' não esteja presente se já foi adicionada
inertia.append(kmeans.inertia_)KMeans(n_clusters=7, n_init=10, random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
plt.figure(figsize=(10, 6))
plt.plot(k_values, inertia, marker='o')
plt.title('Gráfico de Cotovelo para K-Means')
plt.xlabel('Número de Clusters (k)')
plt.ylabel('Inércia (Soma dos Quadrados Intra-Cluster)')
plt.xticks(k_values)([<matplotlib.axis.XTick object at 0x00000245F7F63250>, <matplotlib.axis.XTick object at 0x00000245F7FE16D0>, <matplotlib.axis.XTick object at 0x00000245F7FE1E50>, <matplotlib.axis.XTick object at 0x00000245F7FE25D0>, <matplotlib.axis.XTick object at 0x00000245F7FE2D50>, <matplotlib.axis.XTick object at 0x00000245F7FE34D0>], [Text(2, 0, '2'), Text(3, 0, '3'), Text(4, 0, '4'), Text(5, 0, '5'), Text(6, 0, '6'), Text(7, 0, '7')])plt.grid(True)
plt.show()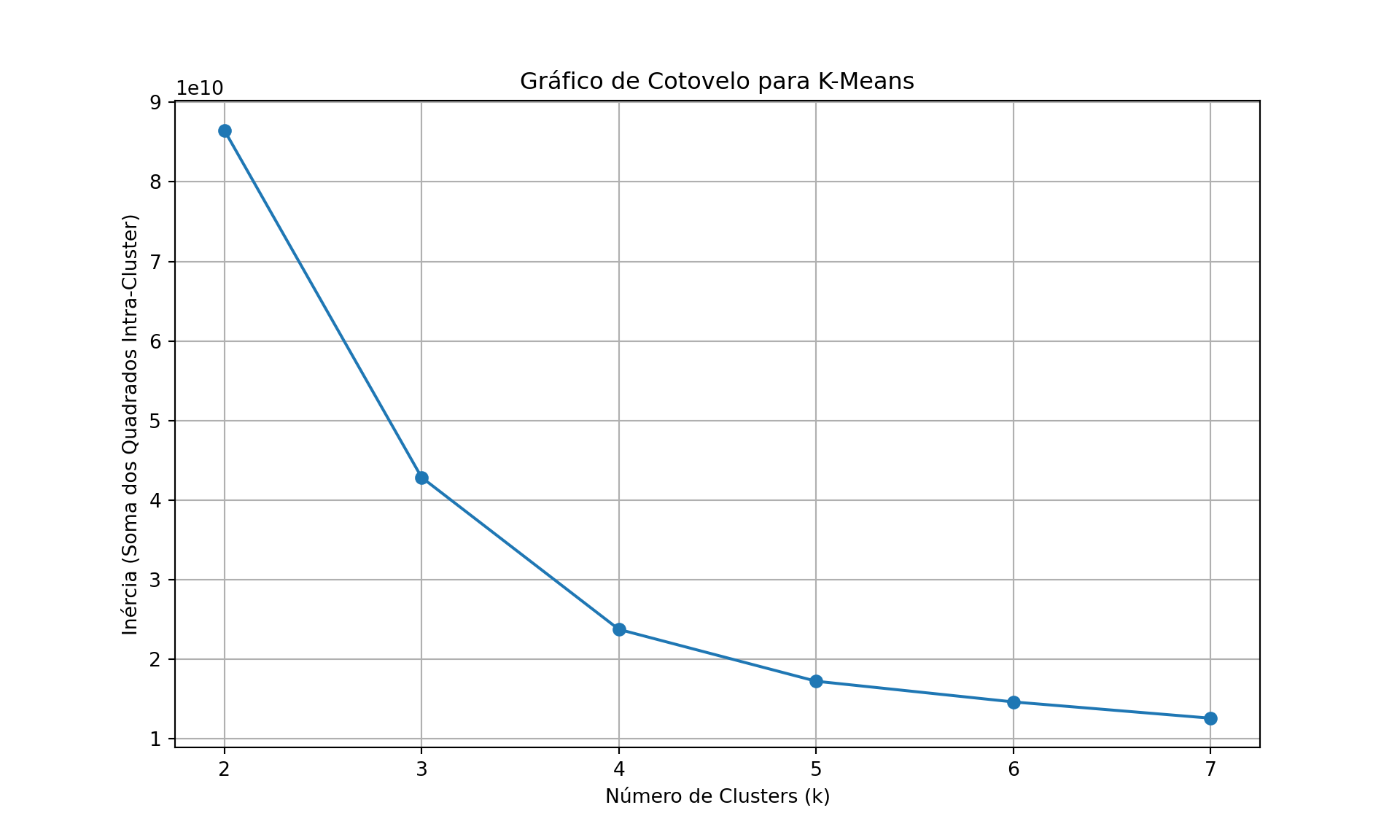
A métrica no eixo \(y\) do gráfico acima é a Inércia (ou Within-Cluster Sum of Squares), que mede a soma das distâncias quadráticas entre cada ponto e o centroide do seu cluster. À medida que aumentamos o número de clusters (\(k\)), a inércia inevitavelmente diminui, pois os grupos ficam menores e mais “apertados”. O objetivo é encontrar o ponto onde o ganho de informação (a queda na inércia) deixa de ser drástico e passa a ser marginal.Interpretação dos ResultadosNo gráfico gerado, observamos uma queda acentuada de \(k=2\) para \(k=3\) e de \(k=3\) para \(k=4\). No entanto, após o 4, a curva suaviza significativamente (o declive se torna menor). Esse “cotovelo” no \(k=4\) indica que adicionar um quinto ou sexto grupo não traria uma melhora substancial na coesão dos dados que justificasse a complexidade extra.
5.4 Visualização dos Clusters através do PCA
O PCA (Análise de Componentes Principais) é uma técnica de redução de dimensionalidade que nos permite visualizar dados de alta dimensão em um espaço 2D ou 3D, preservando a maior parte da variância dos dados. Ao aplicar o PCA aos nossos dados normalizados, podemos plotar os clientes em um gráfico onde cada ponto representa um cliente e a cor indica a qual cluster ele pertence.
Por que PCA aqui? O K-Means calculou os clusters em um espaço de 11 dimensões. É impossível para o ser humano visualizar isso. O PCA projeta essas 11 dimensões em 2 novas (PC1 e PC2) que capturam a maior parte da separação entre os dados.
# 1. Preparação dos Dados para o PCA
# Usamos os dados normalizados (df_cluster), mas removemos a coluna 'cluster' que acabamos de adicionar, pois o PCA só trabalha com variáveis numéricas.
X = df_cluster.drop(columns=['cluster'], errors='ignore')
# 2. Inicialização e Ajuste do PCA
# Queremos reduzir as 11 dimensões originais para apenas 2 componentes principais, permitindo a visualização em um gráfico de dispersão (X, Y).
pca = PCA(n_components=2, random_state=42)
pca_components = pca.fit_transform(X)
# 3. Criação de um DataFrame para Visualização
# Convertemos a matriz resultante do PCA em um DataFrame do Pandas
df_pca = pd.DataFrame(data=pca_components, columns=['PC1', 'PC2'])
# Recuperamos a identificação do cluster (A, B, C, D) do DataFrame original para usar como legenda de cor no gráfico.
df_pca['cluster'] = df_cluster['cluster'].values
# 4. Cálculo da Variância Explicada
var_explicada = pca.explained_variance_ratio_
total_var = var_explicada.sum() * 100
print(f"Variância explicada pelo PC1: {var_explicada[0]*100:.2f}%")Variância explicada pelo PC1: 78.16%print(f"Variância explicada pelo PC2: {var_explicada[1]*100:.2f}%")Variância explicada pelo PC2: 19.63%print(f"Variância total explicada pelos dois componentes: {total_var:.2f}%")Variância total explicada pelos dois componentes: 97.79%# 5. Visualização Gráfica com Seaborn
plt.figure(figsize=(12, 8))
sns.scatterplot(
x='PC1', y='PC2',
hue='cluster', # Define a cor baseada no cluster
palette='Set2', # Mesma paleta usada no gráfico spider
data=df_pca,
alpha=0.3, # Transparência para lidar com a sobreposição de pontos
edgecolor=None # Remove a borda dos pontos para clareza
)
plt.title(f'Visualização dos Clusters em 2D via PCA\n(Variância Total Explicada: {total_var:.1f}%)', size=15)
plt.xlabel(f'Componente Principal 1 ({var_explicada[0]*100:.1f}% var)', size=12)
plt.ylabel(f'Componente Principal 2 ({var_explicada[1]*100:.1f}% var)', size=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()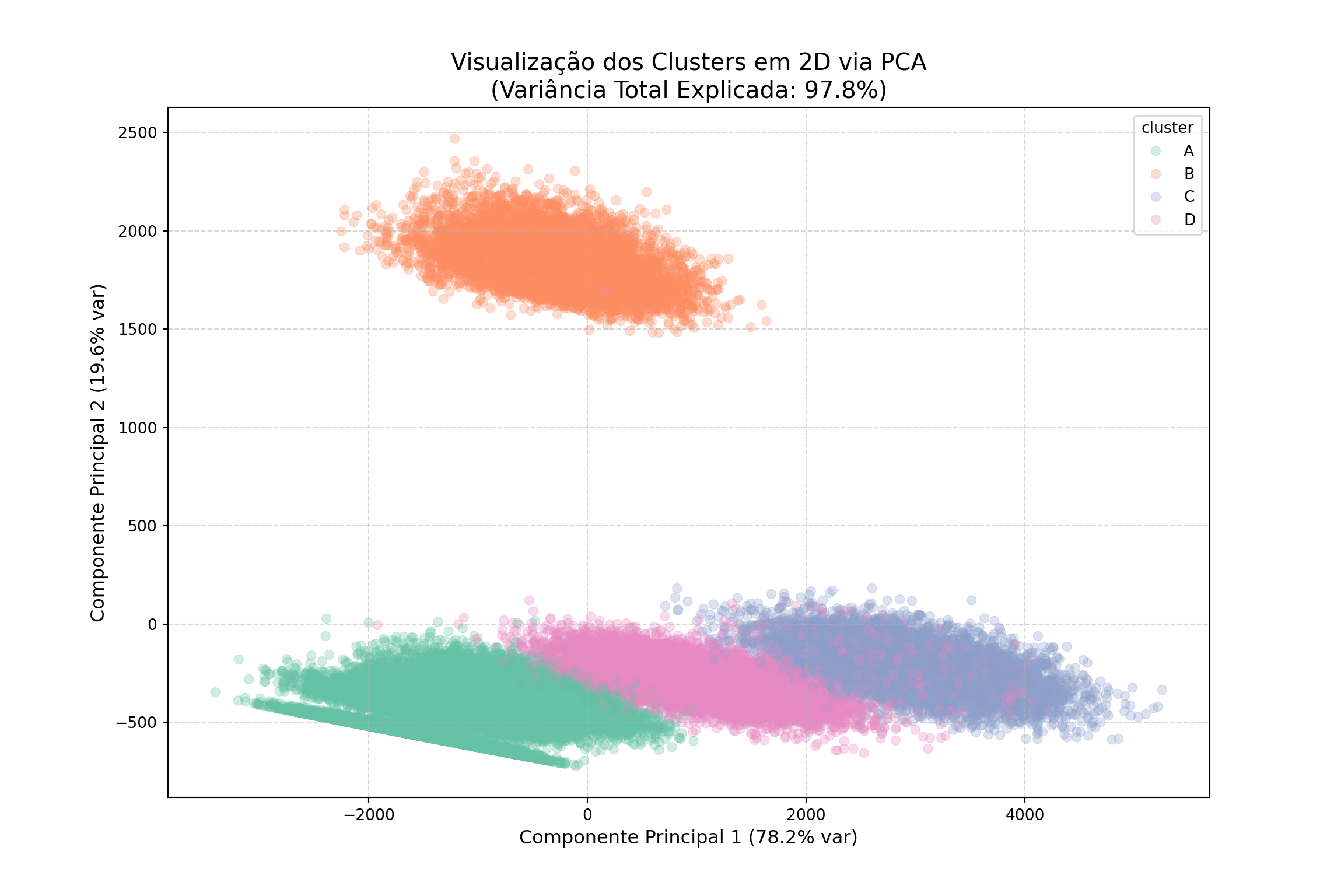
5.5 Discussão
Ao final desta análise, é fundamental refletir sobre a escolha do número de clusters (\(k\)). Embora o Método do Cotovelo aponte para \(k=4\) como o ponto de eficiência estatística, no mundo real, essa decisão é frequentemente exógena ao modelo.
O “K” Estatístico vs. O “K” de Negócio
A escolha final do número de segmentos deve considerar o equilíbrio entre precisão e operacionalidade:
Capacidade de Execução: De que adianta identificar 10 clusters estatisticamente puros se o time de marketing só tem braço para criar 3 campanhas diferentes? Um modelo com muitos grupos pode se tornar ingereciável.
Custo de Implementação: Cada novo segmento exige personalização de catálogo, artes, cupons e logística. Se o ganho de inércia ao passar de \(k=4\) para \(k=5\) é marginal, o custo operacional de gerenciar esse quinto grupo provavelmente não se paga.
Diferenciação Estratégica: O agrupamento só faz sentido se os grupos resultantes exigirem ações de negócio distintas. Se dois clusters identificados pelo algoritmo recebem a mesma oferta de “Desconto em Vinhos”, eles deveriam, na prática, ser tratados como um único segmento.
O algoritmo K-Means nos ofereceu um mapa, mas a navegação é feita pelo gestor. Identificamos que mais de 50% da nossa base (Cluster A) está “dormente”. Este é um insight técnico com uma implicação estratégica massiva: o foco não deve ser em micro-segmentar quem já compra, mas em entender como reativar essa massa inativa.
DicaDesafio Próximo
Como exercício de reflexão: se o orçamento de marketing fosse cortado pela metade, quais desses 4 clusters você deixaria de atender primeiro? Por quê?
5.6 Conclusão
Neste estudo, exploramos o comportamento de uma base de clientes do varejo utilizando o algoritmo \(K\)-means para transformar dados transacionais e demográficos em segmentos acionáveis. O agrupamento bem-sucedido não é aquele que apenas minimiza a inércia, mas aquele que é operacionalizável. De nada adianta uma perfeição estatística se o time de marketing não possui recursos para gerenciar a complexidade de múltiplos segmentos. Portanto, ao implementar esses modelos na prática, deve-se sempre equilibrar a precisão do algoritmo com a capacibilidade de execução da empresa, garantindo que os insights gerados se convertam em decisões que tragam retorno real sobre o investimento.