import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier2 Análise de Manutenção Preditiva
Este case aborda a análise de dados e construção de modelos de classificação para um problema de Manutenção Preditiva. O objetivo é prever se um equipamento apresentará falha (Target) com base em sensores operacionais.
2.1 Configuração e Importação de Dados
Primeiro, importamos as bibliotecas necessárias e carregamos o dataset, predictive_maintainance que está relacionado à manutenção preditiva em um ambiente industrial. Cada linha representa uma observação de um equipamento, com várias variáveis registradas:
- UDI: Identificador único para cada observação.
- Product ID: Identificador do produto associado à observação.
- Type: Tipo do produto ou equipamento.
- Air temperature [K]: Temperatura do ar em Kelvin durante a operação.
- Process temperature [K]: Temperatura do processo em Kelvin durante a operação.
- Rotational speed [rpm]: Velocidade de rotação em rotações por minuto (RPM).
- Torque [Nm]: Torque aplicado durante o processo, medido em Newton-metros (Nm).
- Tool wear [min]: Tempo de desgaste da ferramenta, em minutos.
- Target: Variável alvo, indicando se ocorreu alguma falha ou não.
- Failure Type: Tipo de falha, se houver.
Carregamento do dataset (ajuste o caminho conforme sua máquina).
data = pd.read_csv('data/predictive_maintenance.csv')
data.head(10)| UDI | Product ID | Type | Air temperature [K] | Process temperature [K] | Rotational speed [rpm] | Torque [Nm] | Tool wear [min] | Target | Failure Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | No Failure |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | No Failure |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | No Failure |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | No Failure |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | No Failure |
| 6 | M14865 | M | 298.1 | 308.6 | 1425 | 41.9 | 11 | 0 | No Failure |
2.2 Avaliação Inicial e Análise Descritiva
Vamos entender o tamanho da base, a presença de valores nulos e a distribuição da variável alvo.
print("Número de observações:", data.shape[0])Número de observações: 10000print("Número de variáveis:", data.shape[1])Número de variáveis: 10# Checagem de valores faltantes
print("\nValores faltantes no dataset:\n", data.isnull().sum())
Valores faltantes no dataset:
UDI 0
Product ID 0
Type 0
Air temperature [K] 0
Process temperature [K] 0
Rotational speed [rpm] 0
Torque [Nm] 0
Tool wear [min] 0
Target 0
Failure Type 0
dtype: int64# Checagem de duplicatas
print("\nObservações duplicadas no dataset:", data.duplicated().sum())
Observações duplicadas no dataset: 02.3 Análise Descritiva
Primeiramente, avaliamos a frequência da variável alvo.
# Frequência da variável Target
target_counts = data['Target'].value_counts()
target_percentage = data['Target'].value_counts(normalize=True) * 100
print("\nFrequência da variável Target:\n", target_counts)
Frequência da variável Target:
Target
0 9661
1 339
Name: count, dtype: int64print("\nPorcentagem da variável Target:\n", target_percentage)
Porcentagem da variável Target:
Target
0 96.61
1 3.39
Name: proportion, dtype: float64Frequência das variáveis categóricas.
# Frequência da variável Type
print("Frequência da variável Type:\n", data['Type'].value_counts())Frequência da variável Type:
Type
L 6000
M 2997
H 1003
Name: count, dtype: int64print("\nFrequência da variável Failure Type:\n", data['Failure Type'].value_counts())
Frequência da variável Failure Type:
Failure Type
No Failure 9652
Heat Dissipation Failure 112
Power Failure 95
Overstrain Failure 78
Tool Wear Failure 45
Random Failures 18
Name: count, dtype: int64Estatísticas descritivas das variáveis numéricas.
print("Estatísticas descritivas das variáveis numéricas:\n", data.describe())Estatísticas descritivas das variáveis numéricas:
UDI Air temperature [K] ... Tool wear [min] Target
count 10000.00000 10000.000000 ... 10000.000000 10000.000000
mean 5000.50000 300.004930 ... 107.951000 0.033900
std 2886.89568 2.000259 ... 63.654147 0.180981
min 1.00000 295.300000 ... 0.000000 0.000000
25% 2500.75000 298.300000 ... 53.000000 0.000000
50% 5000.50000 300.100000 ... 108.000000 0.000000
75% 7500.25000 301.500000 ... 162.000000 0.000000
max 10000.00000 304.500000 ... 253.000000 1.000000
[8 rows x 7 columns]2.3.1 Relação das Variáveis com a Target
A matriz de correlação nos ajuda a identificar quais variáveis numéricas possuem maior relação com a ocorrência de falhas.
numeric_data = data.select_dtypes(include=np.number)
correlation_matrix = numeric_data.corr()
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Matriz de Correlação')
plt.show()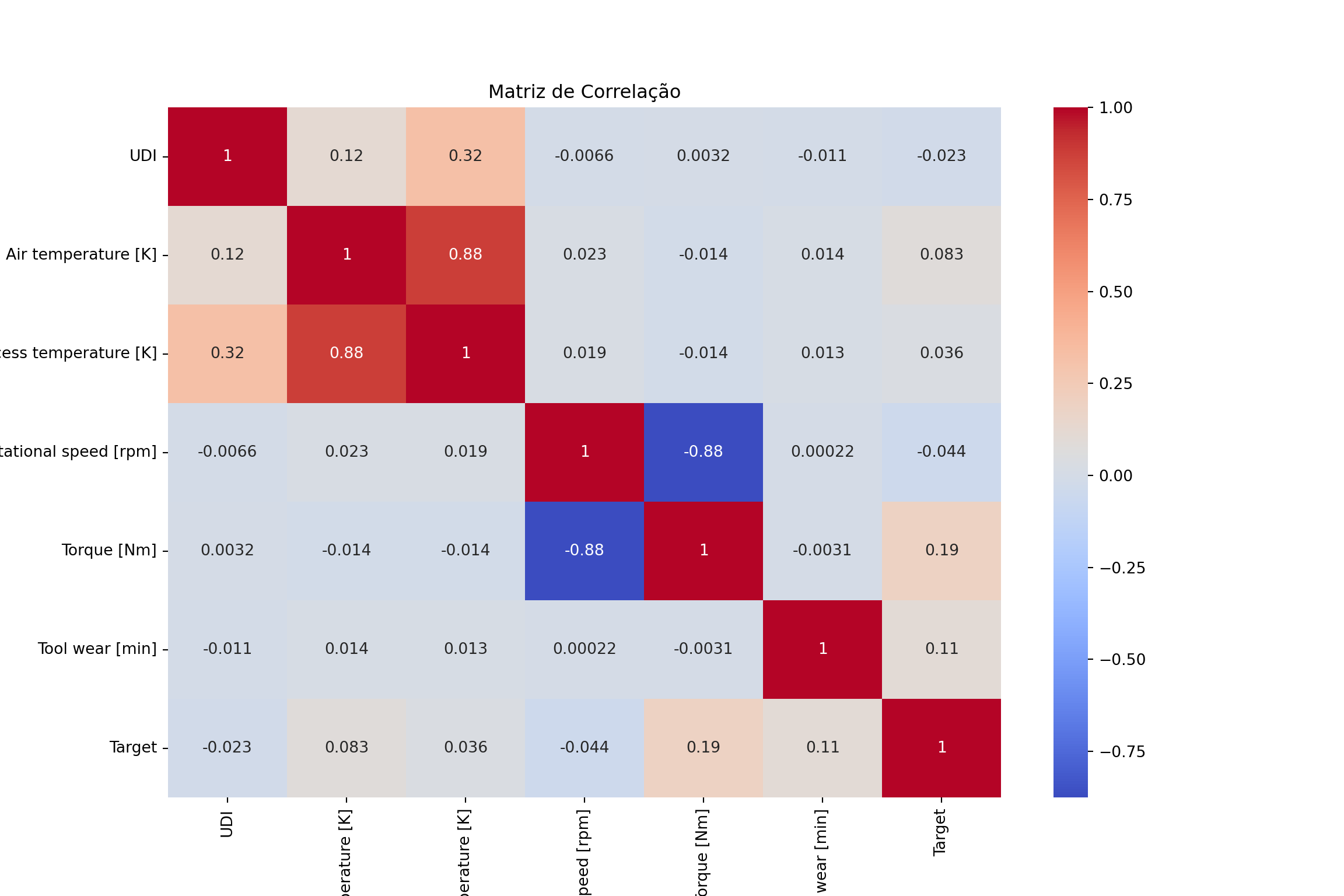
Relação entre a variável Type e a variável Target.
media_target_por_type = data.groupby('Type')['Target'].mean()
print("Média de Target por classe de Type:\n", media_target_por_type)Média de Target por classe de Type:
Type
H 0.020937
L 0.039167
M 0.027694
Name: Target, dtype: float64media_target_por_type = data.groupby('Failure Type')['Target'].mean()
print("\n\nMédia de Target por classe de Failure Type:\n", media_target_por_type)
Média de Target por classe de Failure Type:
Failure Type
Heat Dissipation Failure 1.000000
No Failure 0.000932
Overstrain Failure 1.000000
Power Failure 1.000000
Random Failures 0.000000
Tool Wear Failure 1.000000
Name: Target, dtype: float642.4 Construção do Modelo Preditivo
2.4.1 Preparação dos Dados
Para o modelo, precisamos remover identificadores e transformar variáveis categóricas (como o tipo do produto) em variáveis numéricas (dummies).
Removendo identificadores e colunas de diagnóstico posterior
data_model = data.drop(['UDI', 'Failure Type', 'Product ID'], axis=1)Transformando variáveis categóricas em dummies
data_model = pd.get_dummies(data_model, drop_first=True)Definição das variávei explicativas (features) e da variável alvo (target).
# Definição de X e y
variaveis_explicativas = ['Air temperature [K]', 'Process temperature [K]',
'Rotational speed [rpm]', 'Torque [Nm]', 'Tool wear [min]']
X = data_model[variaveis_explicativas]
y = data_model['Target']Divisão em treino (85%) e validação (15%).
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.15, random_state=42)2.4.2 Treinamento e Comparação de Modelos
Vamos testar quatro algoritmos diferentes: Regressão Logística, Random Forest, KNN e Redes Neurais.
# Inicialização dos modelos
modelos = {
"Regressão Logística": LogisticRegression(),
"Random Forest": RandomForestClassifier(random_state=42),
"KNN": KNeighborsClassifier(),
"Redes Neurais": MLPClassifier(random_state=42)
}
# Função de avaliação para automatizar o processo
def avaliar_modelo(nome, model, X_train, y_train, X_val, y_val):
# O modelo é treinado aqui
model.fit(X_train, y_train)
# Predições
y_pred_train = model.predict(X_train)
y_pred_val = model.predict(X_val)
# Cálculo das métricas de Acurácia
acuracia_train = accuracy_score(y_train, y_pred_train)
acuracia_val = accuracy_score(y_val, y_pred_val)
# Matrizes de Confusão
cm_train = confusion_matrix(y_train, y_pred_train)
cm_val = confusion_matrix(y_val, y_pred_val)
# Cálculo de % de Falsos Positivos e Negativos sobre o TOTAL da amostra
# (Refletindo a lógica exata do seu notebook original)
fp_train = (cm_train[0, 1] / (sum(cm_train[0]) + sum(cm_train[1])))
fn_train = (cm_train[1, 0] / (sum(cm_train[0]) + sum(cm_train[1])))
fp_val = (cm_val[0, 1] / (sum(cm_val[0]) + sum(cm_val[1])))
fn_val = (cm_val[1, 0] / (sum(cm_val[0]) + sum(cm_val[1])))
# Saída formatada para a aula
print(f"--- {nome} ---")
print(f"Acurácia no treino: {acuracia_train:.4f}")
print(f"Acurácia na validação: {acuracia_val:.4f}")
print(f"Matriz de Confusão no treino:\n{cm_train}")
print(f"Matriz de Confusão na validação:\n{cm_val}")
print(f"% de Falsos Positivos no treino: {fp_train:.4%}")
print(f"% de Falsos Negativos no treino: {fn_train:.4%}")
print(f"% de Falsos Positivos na validação: {fp_val:.4%}")
print(f"% de Falsos Negativos na validação: {fn_val:.4%}")
print("\n" + "="*30 + "\n")
for nome, modelo in modelos.items():
avaliar_modelo(nome, modelo, X_train, y_train, X_val, y_val)--- Regressão Logística ---
Acurácia no treino: 0.9699
Acurácia na validação: 0.9707
Matriz de Confusão no treino:
[[8182 26]
[ 230 62]]
Matriz de Confusão na validação:
[[1446 7]
[ 37 10]]
% de Falsos Positivos no treino: 0.3059%
% de Falsos Negativos no treino: 2.7059%
% de Falsos Positivos na validação: 0.4667%
% de Falsos Negativos na validação: 2.4667%
==============================
--- Random Forest ---
Acurácia no treino: 1.0000
Acurácia na validação: 0.9867
Matriz de Confusão no treino:
[[8208 0]
[ 0 292]]
Matriz de Confusão na validação:
[[1449 4]
[ 16 31]]
% de Falsos Positivos no treino: 0.0000%
% de Falsos Negativos no treino: 0.0000%
% de Falsos Positivos na validação: 0.2667%
% de Falsos Negativos na validação: 1.0667%
==============================
--- KNN ---
Acurácia no treino: 0.9738
Acurácia na validação: 0.9700
Matriz de Confusão no treino:
[[8189 19]
[ 204 88]]
Matriz de Confusão na validação:
[[1448 5]
[ 40 7]]
% de Falsos Positivos no treino: 0.2235%
% de Falsos Negativos no treino: 2.4000%
% de Falsos Positivos na validação: 0.3333%
% de Falsos Negativos na validação: 2.6667%
==============================
--- Redes Neurais ---
Acurácia no treino: 0.9656
Acurácia na validação: 0.9687
Matriz de Confusão no treino:
[[8208 0]
[ 292 0]]
Matriz de Confusão na validação:
[[1453 0]
[ 47 0]]
% de Falsos Positivos no treino: 0.0000%
% de Falsos Negativos no treino: 3.4353%
% de Falsos Positivos na validação: 0.0000%
% de Falsos Negativos na validação: 3.1333%
==============================2.5 Análise de Performance por Percentil
Criando um dataframe para consolidar as probabilidades.
df_probabilidades = pd.DataFrame({'Target_Real': y_val})
for nome, modelo in modelos.items():
# Treinando (garantindo que todos estão fitados)
modelo.fit(X_train, y_train)
# Extraindo a probabilidade da classe 1 (falha)
# Nota: Alguns modelos podem não ter predict_proba, mas os selecionados possuem.
df_probabilidades[f'Prob_{nome}'] = modelo.predict_proba(X_val)[:, 1]
print("Primeras linhas do consolidado de probabilidades:")MLPClassifier(random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
print(df_probabilidades.head())| Target_Real | Prob_Regressão Logística | Prob_Random Forest | Prob_KNN | Prob_Redes Neurais | |
|---|---|---|---|---|---|
| 6252 | 0 | 0.0123673 | 0.00 | 0.0 | 7.00e-07 |
| 4684 | 1 | 0.0255143 | 0.00 | 0.0 | 1.20e-06 |
| 1731 | 0 | 0.0135146 | 0.00 | 0.0 | 7.00e-07 |
| 4742 | 0 | 0.0032589 | 0.00 | 0.0 | 4.00e-07 |
| 4521 | 0 | 0.0242423 | 0.00 | 0.0 | 0.00e+00 |
| 6340 | 1 | 0.0479644 | 0.36 | 0.2 | 2.86e-05 |
Agora, vamos calcular a taxa de falha real para cada decil de probabilidade de cada modelo. Um modelo “bom de negócio” deve concentrar quase todas as falhas nos primeiros decis (maior probabilidade).
def calcular_performance_decil(df, col_prob, col_target, nome_modelo):
# Criando os decis
df_temp = df[[col_target, col_prob]].copy()
# Usamos rank para lidar com probabilidades repetidas (comum no KNN e RF)
df_temp['Decil'] = pd.qcut(df_temp[col_prob].rank(method='first'), 10, labels=range(10, 0, -1))
# Agrupando por decil
performance = df_temp.groupby('Decil', observed=True).agg(
total_maquinas=(col_target, 'count'),
falhas_reais=(col_target, 'sum')
).reset_index()
performance['Taxa_Falha'] = performance['falhas_reais'] / performance['total_maquinas']
performance['Modelo'] = nome_modelo
return performance
analise_decis_completa = pd.concat([
calcular_performance_decil(df_probabilidades, f'Prob_{nome}', 'Target_Real', nome)
for nome in modelos.keys()
])Visualização Comparativa
plt.figure(figsize=(12, 6))
sns.lineplot(data=analise_decis_completa, x='Decil', y='Taxa_Falha', hue='Modelo', marker='o')
plt.title('Capacidade de Ordenamento: Taxa de Falha Real por Decil')
plt.ylabel('Taxa de Falha Real (Hit Rate)')
plt.xlabel('Decil de Risco (1 = Mais Provável)')
plt.gca().invert_xaxis() # Inverter para o Decil 10 (maior risco) ficar na esquerda
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()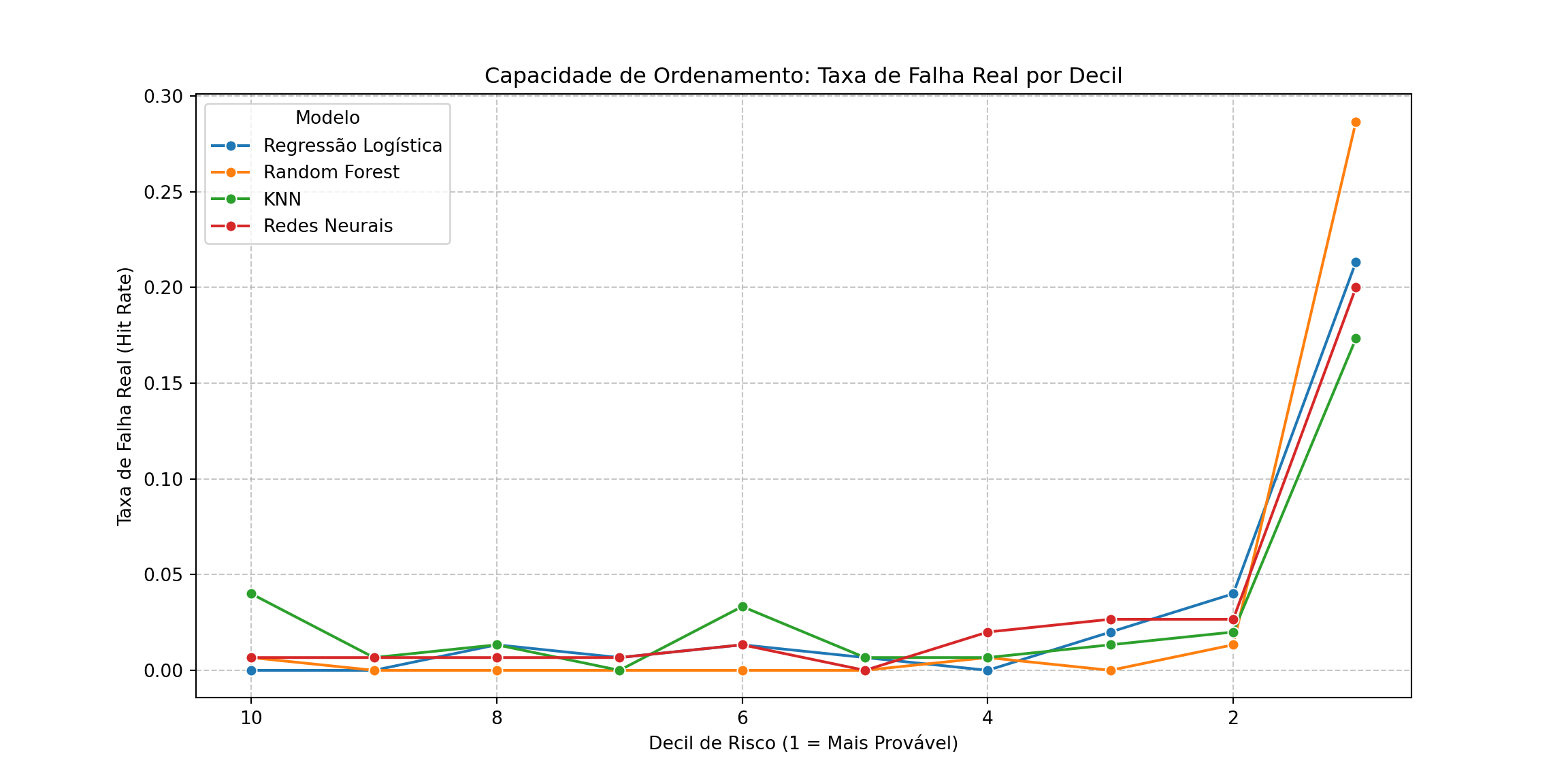
2.6 Impacto Financeiro e Seleção do Modelo
A escolha do “Melhor Modelo” depende do custo do erro. Vamos calcular o impacto financeiro considerando que uma Quebra (Falso Negativo) custa 20x mais que uma Inspeção (Falso Positivo).
def avaliar_custo_modelo(df_probs, col_target, modelos_dict, custo_fp=500, custo_fn=10000):
relatorio_custos = []
for nome in modelos_dict.keys():
# Usando o corte padrão de 0.5 para comparação
preds = (df_probs[f'Prob_{nome}'] >= 0.5).astype(int)
cm = confusion_matrix(df_probs[col_target], preds)
fp = cm[0, 1]
fn = cm[1, 0]
custo_total = (fp * custo_fp) + (fn * custo_fn)
relatorio_custos.append({
'Modelo': nome,
'Falsos Positivos': fp,
'Falsos Negativos': fn,
'Custo Total (R$)': custo_total
})
return pd.DataFrame(relatorio_custos).sort_values('Custo Total (R$)')
df_custos = avaliar_custo_modelo(df_probabilidades, 'Target_Real', modelos)
print("Relatório de Impacto Financeiro (Corte 0.50):")Relatório de Impacto Financeiro (Corte 0.50):print(df_custos) Modelo Falsos Positivos Falsos Negativos Custo Total (R$)
1 Random Forest 4 16 162000
0 Regressão Logística 7 37 373500
2 KNN 5 40 402500
3 Redes Neurais 0 47 470000| Modelo | Falsos Positivos | Falsos Negativos | Custo Total (R$) | |
|---|---|---|---|---|
| 1 | Random Forest | 4 | 16 | 162000 |
| 0 | Regressão Logística | 7 | 37 | 373500 |
| 2 | KNN | 5 | 40 | 402500 |
| 3 | Redes Neurais | 0 | 47 | 470000 |
Ao atribuirmos valores monetários aos erros — R$ 500,00 para uma inspeção desnecessária (FP) e R$ 10.000,00 para uma quebra catastrófica (FN) — a hierarquia dos modelos muda:
O modelo vencedor: Random Forest
- Com um custo total de R$ 162.000, este modelo é o mais eficiente para a operação.
- Sua vantagem reside na baixa taxa de Falsos Negativos (16), provando que cada falha evitada compensa financeiramente até 20 inspeções preventivas sem falha.
- O Random Forest conseguiu o melhor equilíbrio entre sensibilidade e precisão.
A Armadilha das Redes Neurais (O “Modelo Limpinho”)
Embora tenha apresentado 0 Falsos Positivos (precisão perfeita nos alarmes - não “jogar dinheiro fora” com inspeções inúteis), é o pior cenário financeiro (R$ 470.000).
Isso demonstra que o conservadorismo extremo do modelo ignora muitas quebras reais (47 Falsos Negativos), custando caro para a operação.
Apesar de não “jogar dinheiro fora” com inspeções inúteis, ele é o pior modelo financeiramente (R$ 470.000).
Ser conservador demais e só “apontar o dedo” quando se tem certeza absoluta (zero FPs) pode custar uma fortuna em quebras não detectadas (47 Falsos Negativos). Precisão absoluta pode ser um péssimo negócio.
Regressão Logística vs. KNN
- A Regressão Logística é R$ 29.000 mais barata que o KNN, pois capturou 3 falhas a mais, mesmo gerando 2 alarmes falsos adicionais.
Em manutenção preditiva, preferimos modelos “barulhentos” (mais FPs) a modelos “míopes” (mais FNs). A precisão absoluta pode ser um péssimo negócio se o custo da omissão for elevado.
2.7 Próximos Passos
O modelo selecionado para implementação é a Random Forest. Como evolução desta análise, o próximo passo estratégico é:
- Otimização de Threshold: “Podemos ajustar o ponto de corte (threshold) da Random Forest para reduzir os 16 Falsos Negativos ainda mais, mesmo que o número de Falsos Positivos suba para 20 ou 30?”